Difference between revisions of "Working with the HG-WELS data"
m |
m (→TO-DO ITEMS) |
||
| (38 intermediate revisions by the same user not shown) | |||
| Line 5: | Line 5: | ||
=Assembling our initial catalog= | =Assembling our initial catalog= | ||
| − | <font color="red">DONE</font> but kept here for reference because it is | + | <font color="red">DONE</font> but kept here for reference because it is part of the process. LET'S DISCUSS THE QUESTIONS BELOW. |
<!-- '''Big picture goal''': Understand which sources have been studied for these three samples, and what has been measured for them. --> | <!-- '''Big picture goal''': Understand which sources have been studied for these three samples, and what has been measured for them. --> | ||
| Line 24: | Line 24: | ||
#Why is it important to keep track of which stars came from which of these samples? | #Why is it important to keep track of which stars came from which of these samples? | ||
#Why do we not need to assemble more stars from other places? (Both scientific and practical reasons!) | #Why do we not need to assemble more stars from other places? (Both scientific and practical reasons!) | ||
| + | #Can you tell something about the source's origin from its name alone? | ||
#Why did we do this step? (What is the point?) | #Why did we do this step? (What is the point?) | ||
| Line 49: | Line 50: | ||
#Ultimately, for this portion of the process, you will want to assemble source lists from 2MASS, WISE, and IRAS. (For the record, I did these plus many more -- those, plus Akari, Denis, both PSC and FSC from IRAS, MSX, SEIP, and certain bright objects by hand in Vizier.) Pick one of 2MASS, WISE, and IRAS to start with. | #Ultimately, for this portion of the process, you will want to assemble source lists from 2MASS, WISE, and IRAS. (For the record, I did these plus many more -- those, plus Akari, Denis, both PSC and FSC from IRAS, MSX, SEIP, and certain bright objects by hand in Vizier.) Pick one of 2MASS, WISE, and IRAS to start with. | ||
#Do a multi-object search using that IPAC table file. Make sure to use 1-to-1 matching -- this option finds the source closest to your search position within your given search radius, and returns one line per object, even one line for those things that did not find a match. This greatly helps with the next steps. | #Do a multi-object search using that IPAC table file. Make sure to use 1-to-1 matching -- this option finds the source closest to your search position within your given search radius, and returns one line per object, even one line for those things that did not find a match. This greatly helps with the next steps. | ||
| − | #Look at what it gives you in response to your search. It comes up with a plot of distance to your source as a function of source number. Why is this important? Is there a place in the list where it gets much worse? Why is this? | + | #Look at what it gives you in response to your search. It comes up with a plot of the first two numeric columns in the search results, which is most likely distance to your source as a function of source number. Why is this metric important? Is there a place in the list where it gets much worse? Why is this? |
#Save the output of the search to a file. Rename it and put it someplace you can find it. | #Save the output of the search to a file. Rename it and put it someplace you can find it. | ||
| − | #Circle back and repeat for the rest of 2MASS, WISE, and IRAS. You will need a smallish radius for 2MASS and a largish radius for WISE and IRAS. (I used, I think, 5 arcsec for 2MASS and 20 arcsec for WISE and IRAS.) | + | #Circle back and repeat for the rest of 2MASS, WISE, and IRAS. You will need a smallish radius for 2MASS and a largish radius for WISE and IRAS. (I used, I think, 5 arcsec for 2MASS and 20 arcsec for WISE and IRAS. (Note: These limits are appropriate for two reasons: (a) the 1-to-1 takes the closest match, so if there is 1 source within 1 arcsec and 10 within 5 arcsec, it will still grab the one source within 1 arcsec; (b) some of our input coordinates are very bad, so searching just with a 1 arcsec radius isn't going to find anything. If, in the future, you have high-quality coordinates, 1 arcsec will be sufficient for 2MASS and even WISE, and probably 2-3 arcsec for IRAS.) |
| − | #Note that, as long as you use the same input tbl file every time and choose 1-to-1 matching every time, there is always the same number of lines in the output file. This makes matching across catalogs very easy. Note that all catalogs return the same columns (source name, input ra/dec, matched source id, matched source ra/dec), as well as a wide variety of additional columns. Identify the columns out of these catalogs that you actually need. (Work with the group to identify which columns you need. Hint: the photometric measurements, the errors on them, and the phot quality flags.) | + | #Note that, as long as you use the same input tbl file every time and choose 1-to-1 matching every time, there is always the same number of lines in the output file, in the same order as the input file. This makes matching across catalogs very easy. Note that all catalogs return the same columns (source name, input ra/dec, matched source id, matched source ra/dec), as well as a wide variety of additional columns. Identify the columns out of these catalogs that you actually need. (Work with the group to identify which columns you need. Hint: the photometric measurements, the errors on them, and the phot quality flags.) |
#Start an Excel file. Read in one of the search results tbl files. Delete the columns you don't need. Repeat for the other search results tbl files. Copy and paste ''very carefully'' to match the same source across all the catalogs into one Excel sheet, such that in the end you have one row per object with all the relevant resulting information you have discovered about these sources. Save often! This process is sometimes called "bandmerging" because it is merging across bands (wavelengths). | #Start an Excel file. Read in one of the search results tbl files. Delete the columns you don't need. Repeat for the other search results tbl files. Copy and paste ''very carefully'' to match the same source across all the catalogs into one Excel sheet, such that in the end you have one row per object with all the relevant resulting information you have discovered about these sources. Save often! This process is sometimes called "bandmerging" because it is merging across bands (wavelengths). | ||
#Spot check some sources. Are there sources bright at all bands? | #Spot check some sources. Are there sources bright at all bands? | ||
| Line 63: | Line 64: | ||
=Checking that the coordinates and photometry make sense, part 1 - image inspection= | =Checking that the coordinates and photometry make sense, part 1 - image inspection= | ||
| − | <font color="red">DONE</font> -- at least a first pass. | + | <font color="red">DONE</font> -- at least a first pass. As for above, we should discuss the questions below! |
<!-- '''Big picture goal''': Check to make sure we have sensible matches. Just because the computer says it, does not make it right. Always check to make sure that the computer is correct. (AKA "count your change.") | <!-- '''Big picture goal''': Check to make sure we have sensible matches. Just because the computer says it, does not make it right. Always check to make sure that the computer is correct. (AKA "count your change.") | ||
| Line 73: | Line 74: | ||
'''Minimal additional words''': | '''Minimal additional words''': | ||
| − | + | Get your list of input sources, and pass it to FinderChart at IRSA. Inspect every source at POSS, SDSS if it exists, 2MASS, WISE, and Spitzer. For each source, look to see if we have the coordinates right. Is it just one point source? This is one of the major goals of our work, to determine if there is "source confusion" at these locations. You may need to loop back to the prior step after doing this. I did. (Note that we already identified coordinate issues in this step, which would be one reason to go back!) After doing the SED inspection below, you will probably need to loop back to this and the prior step to check things. I did. | |
| − | |||
'''Questions for you''': | '''Questions for you''': | ||
| Line 91: | Line 91: | ||
Make at least one SED yourself. ---> | Make at least one SED yourself. ---> | ||
| − | Make sure you understand how to get the | + | Make sure you understand how to get the flux densities from the magnitudes, and how to convert flux density into energy density. This is not easy to do right the first time, so you will get the wrong answer the first few times you try. |
'''Relevant links''': | '''Relevant links''': | ||
| Line 97: | Line 97: | ||
*[[SED plots]] | *[[SED plots]] | ||
*[[Central wavelengths and zero points]] | *[[Central wavelengths and zero points]] | ||
| + | *[[Step-by-step SED assembly]] | ||
| − | We (or, possibly, "we") will ultimately need to make SEDs for everything, for all bands, but to make this tractable for your visit, let's work with just the bands you merged above (2MASS, IRAS, WISE) and just a few sources. Let's | + | We (or, possibly, "we") will ultimately need to make SEDs for everything, for all bands, but to make this tractable for your visit, let's work with just the bands you merged above (2MASS, IRAS, WISE) and just a few sources. Let's start with just these five so that we can have a sensible group discussion. Note that I did not pick these five randomly! : |
*Tyc3340-01195-1 | *Tyc3340-01195-1 | ||
*HD6665 | *HD6665 | ||
| Line 121: | Line 122: | ||
=Checking that the coordinates and photometry make sense, part 2 - SED inspection= | =Checking that the coordinates and photometry make sense, part 2 - SED inspection= | ||
| − | ''In an ideal world, you'd make all the SEDs for all the bands to which we have access, identify those with photometry issues | + | ''In an ideal world, you'd make all the SEDs for all the bands to which we have access, compare them to the notes you've already made about the images, identify those with photometry issues and fix those (manually if necessary), AND make SEDs again. If you were programming in Python, you'd have a shot at making a first pass at fully-populated SEDs in less than an hour or two, but even for me, tracking down all the photometry issues was ~2-3 days. Let's not waste that time right here, right now; let's use my SEDs and jump into the next step.'' |
<!-- '''Big Picture Goal''': Go through and look at each and every SED. From the SEDs, you can look and see if the photometry assembled from all the catalogs above make sense, and see if there is an obvious IR excess you can see, or if the excess likely involves more than one band. --> | <!-- '''Big Picture Goal''': Go through and look at each and every SED. From the SEDs, you can look and see if the photometry assembled from all the catalogs above make sense, and see if there is an obvious IR excess you can see, or if the excess likely involves more than one band. --> | ||
| Line 134: | Line 135: | ||
'''More words''': | '''More words''': | ||
| − | Obtain my set of SEDs from email. In my SEDs, I use the following symbols for particular surveys. Vertical black lines through any point is the error on the point; in many cases, the error bar is very small. Go through all of the SEDs. You will need to look for three things -- see the questions below. Keep notes on this. | + | Obtain my set of SEDs from email. In my SEDs, I use the following symbols for particular surveys. Vertical black lines through any point is the error on the point; in many cases, the error bar is very small. Go through all of the SEDs. You will need to look for three or four things -- see the questions below. Keep notes on this. |
{| class="wikitable" | {| class="wikitable" | ||
|- | |- | ||
| Line 188: | Line 189: | ||
'''Questions or Tasks for you:''' | '''Questions or Tasks for you:''' | ||
| + | #Go through the sources assigned to you and your partner. Make notes on the SEDs, including any you would like to discuss with more people (e.g., discuss with the group). As you go through, specifically consider the next few questions as well. | ||
#Make a list of sources where there are things that seem wrong in the SED - things suggestive of a source mismatch (e.g., source seen at optical is NOT source seen at NIR, is NOT source seen at MIR, etc) - or things suggestive of a photometry problem. We can use this information to circle back and repeat the search for photometric matches above. (In fact, I did exactly this over the course of about 2-3 days.) | #Make a list of sources where there are things that seem wrong in the SED - things suggestive of a source mismatch (e.g., source seen at optical is NOT source seen at NIR, is NOT source seen at MIR, etc) - or things suggestive of a photometry problem. We can use this information to circle back and repeat the search for photometric matches above. (In fact, I did exactly this over the course of about 2-3 days.) | ||
#Make a list of sources where IRAS fluxes are too bright given the new WISE information. This is another facet of one of our big science goals - seeing where WISE resolves source confusion means both where there are multiple sources and where there is just high surface brightness from the nebulosity contaminating the IRAS measurements. | #Make a list of sources where IRAS fluxes are too bright given the new WISE information. This is another facet of one of our big science goals - seeing where WISE resolves source confusion means both where there are multiple sources and where there is just high surface brightness from the nebulosity contaminating the IRAS measurements. | ||
#Make a list of sources whose SEDs suggest that they may be non-stellar. This is yet another facet of our science goals - identifying which objects are not likely red giants. | #Make a list of sources whose SEDs suggest that they may be non-stellar. This is yet another facet of our science goals - identifying which objects are not likely red giants. | ||
| − | #As you are going along, can you tell at a glance whether or not any given object has an IR excess? (This may be easier if you managed to put an RJ (Rayleigh-Jeans) line on your SEDs, but still.) What constitutes an excess? Where are you looking to compare points to see whether or not there is an excess? (These are all leading questions, setting up the next several steps.) | + | #As you are going along, can you tell at a glance whether or not any given object has an IR excess? (This may be easier if you managed to put an RJ (Rayleigh-Jeans) line on your SEDs, but still.) What constitutes an excess? Where are you looking to compare points to see whether or not there is an excess? (These are all leading questions, setting up the next several steps.) |
| + | #What bands do we have for the most sources? | ||
#Why did we do this step? (What is the point?) | #Why did we do this step? (What is the point?) | ||
| Line 218: | Line 221: | ||
*Also see slides from my set of talks on Monday. | *Also see slides from my set of talks on Monday. | ||
| − | + | In looking for stars with excesses, it will help to look at the distributions of K-[22] or [3.4]-[22] (or whatever other combination you've found above) as a function of other parameters. | |
| − | In looking for stars with excesses, it will help to look at the distributions of K-[22] or [3.4]-[22] as a function of other parameters. | ||
| − | Make a color-magnitude diagram for the ensemble of sources. K vs K-[22] and/or [3.4] vs. [3.4]-[22] are good places to start. Pay attention to detections (not limits). You may want to use IRSA Viewer rather than Excel because then you can pick out individual sources that are outliers and see immediately which source they are. However, you need to get the catalog into IPAC Table format first in order to make that happen, so you may decide that Excel is easier. | + | Make a color-magnitude diagram for the ensemble of sources. K vs K-[22] and/or [3.4] vs. [3.4]-[22] are good places to start, but feel free to try other combinations. Pay attention to detections (not limits). You may want to use IRSA Viewer rather than Excel because then you can pick out individual sources that are outliers and see immediately which source they are. However, you need to get the catalog into IPAC Table format first in order to make that happen, so you may decide that Excel is easier. |
You may want to start color-coding points based on the sample from which they come (de la Reza original? Joleen's unbiased sample?). | You may want to start color-coding points based on the sample from which they come (de la Reza original? Joleen's unbiased sample?). | ||
| Line 237: | Line 239: | ||
[[file:doesithaveirx.png|right|200px]] | [[file:doesithaveirx.png|right|200px]] | ||
#On Monday, what did I say should be the IR color of plain photospheres? | #On Monday, what did I say should be the IR color of plain photospheres? | ||
| − | #On Monday, I also showed a movie of blackbody curves as a function of temperature. When might the IR color of plain photospheres change? | + | #On Monday, I also showed a movie of blackbody curves as a function of temperature. (it is here if you want to view it again: https://www.youtube.com/watch?v=mjfSy2kHWqQ ) When might the IR color of plain photospheres change? |
| − | #One way to decide if we need to worry about this is to plot things as a function of temperature. Out of the data that we have, are there any color indices that are a sensitive function of temperature? | + | #One way to decide if we need to worry about this is to plot things as a function of temperature. Out of the data that we have, are there any color indices that are a sensitive function of temperature? (Hint: watch the movie again) |
| − | #Try plotting V-K against K-[22] or [3.4]-[22]. Are there any we need to worry about? | + | #Try plotting V-K against K-[22] or [3.4]-[22]. Are there any we need to worry about? (you can get a grid of expected colors as a function of spectral type from me.) |
#What should the predicted [3.4]-[22] be in this equation? [[image:obsminusexp.png]] Now you should have a better sense of what this equation might mean. | #What should the predicted [3.4]-[22] be in this equation? [[image:obsminusexp.png]] Now you should have a better sense of what this equation might mean. | ||
#Are there still objects for which you are unsure if they have IR excesses? ''(hint: yes)'' | #Are there still objects for which you are unsure if they have IR excesses? ''(hint: yes)'' | ||
| Line 249: | Line 251: | ||
By now, you should already have found some IR excess objects. But, especially for this data set, we have a LOT more sources where the IR excess is ambiguous. You can't necessarily tell just by looking at the SED or the color. You need to calculate whether or not it has an excess, and you need to worry about the uncertainty on the measurements (the measurement errors). | By now, you should already have found some IR excess objects. But, especially for this data set, we have a LOT more sources where the IR excess is ambiguous. You can't necessarily tell just by looking at the SED or the color. You need to calculate whether or not it has an excess, and you need to worry about the uncertainty on the measurements (the measurement errors). | ||
| − | [[image:chicalc.png]] Here is the calculation from our proposal. You now know what to put in the numerator. The denominator is the uncertainty on the color. To get the uncertainty on the color, add the uncertainties from each point (that goes into the color) ''in quadrature''. What this means: (error on x-y)^2 = (error on x)^2 + (error on y)^2. | + | [[image:chicalc.png]] Here is the calculation from our proposal. You now know what to put in the numerator. The denominator is the uncertainty on the color. To get the uncertainty on the color, add the uncertainties from each point (that goes into the color) ''in quadrature''. What this means: (error on x-y)^2 = (error on x)^2 + (error on y)^2. Note that even though we are calculating the difference in values (x-y), the errors still ADD (in quadrature). |
This chi is an estimate of significance -- the signal divided by the noise, or the measurement divided by the error. | This chi is an estimate of significance -- the signal divided by the noise, or the measurement divided by the error. | ||
| Line 262: | Line 264: | ||
=Calculating excesses, part 5: Further muddying the waters= | =Calculating excesses, part 5: Further muddying the waters= | ||
| − | Astronomical data are VERY hard to precisely calibrate. The 2MASS folks, the Denis folks, and the WISE folks (and for that matter, all the other teams too) all calibrated their instruments slightly differently. It could be that small excesses are not real dust around the star, but absolute calibration uncertainties in the way the data were reduced. Are there any sources for which you are worried that this might be the case? In this sense, since the WISE bands were all calibrated the same way by the same people, a comparison of two WISE bands may be the most sensitive measure we can have of IR excess. | + | Astronomical data are VERY hard to precisely calibrate. The 2MASS folks, the Denis folks, and the WISE folks (and for that matter, all the other teams too) all calibrated their instruments slightly differently. It could be that small excesses we measure are not real dust around the star, but absolute calibration uncertainties in the way the data were reduced. Are there any sources for which you are worried that this might be the case? In this sense, since the WISE bands were all calibrated the same way by the same people, a comparison of two WISE bands may be the most sensitive measure we can have of IR excess. |
These stars intrinsically vary. K measured at one time may not be at all the same as the K measured at another time, and not for source mismatch reasons, but real, astrophysical variations -- our Sun has sunspot cycles, and other stars do too. If one measurement was obtained at a low point in the starspot cycle, and another measurement was obtained at a high point in the starspot cycle, the measurements will be legitimately different. In that sense, since the WISE bands were obtained essentially simultaneously, WISE data should be the best data for a comparison of two bands, since the star itself will not have had time to significantly change between WISE measurements. | These stars intrinsically vary. K measured at one time may not be at all the same as the K measured at another time, and not for source mismatch reasons, but real, astrophysical variations -- our Sun has sunspot cycles, and other stars do too. If one measurement was obtained at a low point in the starspot cycle, and another measurement was obtained at a high point in the starspot cycle, the measurements will be legitimately different. In that sense, since the WISE bands were obtained essentially simultaneously, WISE data should be the best data for a comparison of two bands, since the star itself will not have had time to significantly change between WISE measurements. | ||
| Line 271: | Line 273: | ||
Why is this step here? (What is the point?) | Why is this step here? (What is the point?) | ||
| − | |||
=Comparison to the literature and start of the bigger picture= | =Comparison to the literature and start of the bigger picture= | ||
| Line 292: | Line 293: | ||
#For each sub-sample, what is the IR excess fraction? At what wavelengths? | #For each sub-sample, what is the IR excess fraction? At what wavelengths? | ||
#For the Carlberg sample (the cleanest with respect to input biases), plot a measure of IR excess (your choice) vs. some of the parameters that Carlberg thought were important in her paper -- vsini, A(Li), Vmag, carbon isotope ratio, and anything else you can find. Do you see anything that is worth thinking more about? | #For the Carlberg sample (the cleanest with respect to input biases), plot a measure of IR excess (your choice) vs. some of the parameters that Carlberg thought were important in her paper -- vsini, A(Li), Vmag, carbon isotope ratio, and anything else you can find. Do you see anything that is worth thinking more about? | ||
| − | #Why did we do this step? (What is the point?) | + | #Why did we do this step? (What is the point?) Could we have done this step earlier? |
| + | |||
| + | =TO-DO ITEMS= | ||
| + | #DONE Luisa to clean up limits in code such that lower/upper limits make sense in catalog and plots | ||
| + | #DONE Luisa to fix photometry issues for those identified from the SED inspection as being bad. (Also, see if we can reconstruct some of he WISE 1-2 values, based on the saturation correction from Patel+ or just by looking more closely at data quality flags.) | ||
| + | #DONE Luisa to investigate whether it makes sense to swap DENIS K in for 2MASS K where there is no 2MASS K. | ||
| + | #DONE Luisa to remake the SEDs for those with fixed photometry. | ||
| + | #(Luisa has made headway on) Make clear and complete lists of those objects that break into pieces in IRAS, those that have coordinate issues, and those that have SEDs inconsistent with stars. Keep track of which sources came from which original catalog such that we can report, e.g., "xx% of the sources published in de la Reza break into pieces when viewed with WISE." | ||
| + | #Integrate notes from image inspection with the SED inspection (e.g., in more detail). Combine cells and information where needed to make as concise as possible. | ||
| + | #For each "not a star", search in Simbad and the literature to see if anyone has any other information about the object. | ||
| + | #Extra credit options: add errors to SEDs. Add Rayleigh-Jeans line to SEDs. | ||
| + | #WATCH FOR LIMITS. make plots of just detections, not limits. | ||
| + | #Make some color-color and color-mag diagrams for subsets of data by original catalog, AND/OR color-code the points in the diagrams to match original source catalog. | ||
| + | #Investigate the photometry on those with VERY large K-[22] or [3.4]-[22]. Are values greater than 6 real, physical values? What do those SEDs look like? | ||
| + | #Find objects where the chi is insanely large. Are those real? What do those SEDs look like? Are the chi values we calculate realistic? | ||
| + | #Find objects where chi calculated for two bands does NOT agree with the chi calculated for another two bands? Go get the SEDs for them and see if you can figure out why the math is coming out the way that it is. | ||
| + | #Do some analysis on the ensemble of points for K-[22] and [3.4]-[22] to see which distribution makes more sense, incorporates more objects, has lower scatter. Decide which we should use in the end. | ||
| + | #Investigate whether [4.5]-[22] would be worth considering. Note that the correction for saturated WISE2 is much larger than the correction for WISE1. | ||
| + | #Worry about those with chi near to but not over 3. Are there any reasons we should take them as IR x sources? | ||
| + | #What about plots vs. chi? | ||
| + | #Can we reproduce plot from literature? Where are the obj that we know are not stars, or for which wise indicates lower fluxes than iras? | ||
Latest revision as of 20:37, 28 August 2014
This page is similar in concept to the summer visit pages for my prior teams (Working with the C-CWEL data; Working with the C-WAYS data page; Working with the BRCs; Working with CG4+SA101 page; Working with L1688) HOWEVER, this page was developed and updated specifically for the 2014 HG-WELS team visit. Because this team has a very different science goal, it is very different, for the most part, than these other pages.
Please note: NONE of these pages are meant to be used without applying your brain! They are NOT cookbooks! This is presented as a linear progression because of the nature of this page, but we have already done some things "out of order", and moreover, chances are excellent that you will go back and redo different pieces of this at different stages of your work.
Contents
- 1 Assembling our initial catalog
- 2 Assembling other data from large catalogs
- 3 Checking that the coordinates and photometry make sense, part 1 - image inspection
- 4 Making SEDs
- 5 Checking that the coordinates and photometry make sense, part 2 - SED inspection
- 6 Calculating excesses, part 1
- 7 Calculating excesses, part 2: Making CMDs
- 8 Calculating excesses, part 3: Making different color-color diagrams
- 9 Calculating excesses, part 4: Significance of excesses
- 10 Calculating excesses, part 5: Further muddying the waters
- 11 Comparison to the literature and start of the bigger picture
- 12 The bigger picture
- 13 TO-DO ITEMS
Assembling our initial catalog
DONE but kept here for reference because it is part of the process. LET'S DISCUSS THE QUESTIONS BELOW.
We assembled our catalog in the spring from three sources:
- de la Reza's published catalog - biased towards sources bright in the IR
- Carlberg's published catalog - much less biased set of giants assembled without regard to IR or Li, spanning range of vsini
- Carlberg's private communication set of objects mentioned in the literature as Li rich (some of which subsequently vanished from de la reza's papers)
We have a list of 196 unique objects that we assembled, keeping track of where the source was listed. Some objects are listed in more than one of those three places.
Relevant links:
- How can I find out what scientists already know about a particular astronomy topic or object?
- I'm ready to go on to the "Advanced" Literature Searching section
- HG-WELS Bigger Picture and Goals
Questions for you
- Why is it important to keep track of which stars came from which of these samples?
- Why do we not need to assemble more stars from other places? (Both scientific and practical reasons!)
- Can you tell something about the source's origin from its name alone?
- Why did we do this step? (What is the point?)
Assembling other data from large catalogs
Luisa did this in its full glory but we need to do a few as a check and so you understand what I did...and so you can do it yourself later on your own for other projects.
Relevant links:
- How can I get data from other wavelengths to compare with infrared data from Spitzer? - though that wiki page focuses more on imaging. We need photometry.
- FinderChart at IRSA
- IRSA in general
- Catalog search at IRSA IMPORTANT AND NEW TO YOU
- Resolution - spatial resolution matters!
- HG-WELS Resolution Worksheet - the worksheet we did in the Spring
- Vizier
- YouTube Video Tutorial from IRSA about catalog searches
More words: Several surveys with archived data covered the whole sky. There are other surveys that just covered part of the sky. We are trying ultimately to determine if these sources have infrared (IR) excesses. We would like to assemble data from as many places as we can to flesh out the SEDs between optical (V-band) and 100 microns (the longest IRAS wavelength). As we spelled out in the proposal, the meat of what we are likely to use is probably going to be WISE 1 and WISE 4, or possibly K and WISE 4. But, as we will see below, having additional data can REALLY help us to assess whether or not we believe the two bands we will use to determine whether or not our sources have IR excesses.
- Get from your email (or assemble yourself) an IPAC table file with all our targets and their positions in decimal ra/dec.
- Go to the catalog search at IRSA
- Ultimately, for this portion of the process, you will want to assemble source lists from 2MASS, WISE, and IRAS. (For the record, I did these plus many more -- those, plus Akari, Denis, both PSC and FSC from IRAS, MSX, SEIP, and certain bright objects by hand in Vizier.) Pick one of 2MASS, WISE, and IRAS to start with.
- Do a multi-object search using that IPAC table file. Make sure to use 1-to-1 matching -- this option finds the source closest to your search position within your given search radius, and returns one line per object, even one line for those things that did not find a match. This greatly helps with the next steps.
- Look at what it gives you in response to your search. It comes up with a plot of the first two numeric columns in the search results, which is most likely distance to your source as a function of source number. Why is this metric important? Is there a place in the list where it gets much worse? Why is this?
- Save the output of the search to a file. Rename it and put it someplace you can find it.
- Circle back and repeat for the rest of 2MASS, WISE, and IRAS. You will need a smallish radius for 2MASS and a largish radius for WISE and IRAS. (I used, I think, 5 arcsec for 2MASS and 20 arcsec for WISE and IRAS. (Note: These limits are appropriate for two reasons: (a) the 1-to-1 takes the closest match, so if there is 1 source within 1 arcsec and 10 within 5 arcsec, it will still grab the one source within 1 arcsec; (b) some of our input coordinates are very bad, so searching just with a 1 arcsec radius isn't going to find anything. If, in the future, you have high-quality coordinates, 1 arcsec will be sufficient for 2MASS and even WISE, and probably 2-3 arcsec for IRAS.)
- Note that, as long as you use the same input tbl file every time and choose 1-to-1 matching every time, there is always the same number of lines in the output file, in the same order as the input file. This makes matching across catalogs very easy. Note that all catalogs return the same columns (source name, input ra/dec, matched source id, matched source ra/dec), as well as a wide variety of additional columns. Identify the columns out of these catalogs that you actually need. (Work with the group to identify which columns you need. Hint: the photometric measurements, the errors on them, and the phot quality flags.)
- Start an Excel file. Read in one of the search results tbl files. Delete the columns you don't need. Repeat for the other search results tbl files. Copy and paste very carefully to match the same source across all the catalogs into one Excel sheet, such that in the end you have one row per object with all the relevant resulting information you have discovered about these sources. Save often! This process is sometimes called "bandmerging" because it is merging across bands (wavelengths).
- Spot check some sources. Are there sources bright at all bands?
Questions for you (in addition to the ones embedded above):
- Why does resolution matter?
- How will this process fail, if/when it fails?
- Why did we do this step? (What is the point?)
Checking that the coordinates and photometry make sense, part 1 - image inspection
DONE -- at least a first pass. As for above, we should discuss the questions below!
Relevant links:
- FinderChart at IRSA
- Resolution - spatial resolution matters!
Minimal additional words: Get your list of input sources, and pass it to FinderChart at IRSA. Inspect every source at POSS, SDSS if it exists, 2MASS, WISE, and Spitzer. For each source, look to see if we have the coordinates right. Is it just one point source? This is one of the major goals of our work, to determine if there is "source confusion" at these locations. You may need to loop back to the prior step after doing this. I did. (Note that we already identified coordinate issues in this step, which would be one reason to go back!) After doing the SED inspection below, you will probably need to loop back to this and the prior step to check things. I did.
Questions for you:
- One of our major scientific goals here is to identify sources that are not good single, red giant candidates. Which are the sources that need the most scrutiny for this?
- Locate the most recent version of the merged source list with all our comments combined. (You may need to check email.) Using that information, assemble a list of these sources that become more than one piece. Since this is a major goal of our work, we will need to report that "XX sources from YY list broke into pieces when viewed with WISE." Assemble what you need to write that sort of sentence.
- Why did we do this step? (What is the point?)
Making SEDs
Luisa made full SEDs in their full glory but we need to do a few as a check and so you understand what I did, and so that you can make some of the CMDs we will get to below.
WARNING: lots of math and programming spreadsheets... you WILL do this more than once to get the units right!
Make sure you understand how to get the flux densities from the magnitudes, and how to convert flux density into energy density. This is not easy to do right the first time, so you will get the wrong answer the first few times you try.
Relevant links:
We (or, possibly, "we") will ultimately need to make SEDs for everything, for all bands, but to make this tractable for your visit, let's work with just the bands you merged above (2MASS, IRAS, WISE) and just a few sources. Let's start with just these five so that we can have a sensible group discussion. Note that I did not pick these five randomly! :
- Tyc3340-01195-1
- HD6665
- IRAS07227-1320
- HIP36896
- IRAS11044-6127
Start with just one. You will ultimately plot log (lambda*F(lambda)) vs log (lambda) -- see the Units page. It will take time to get the units right, but once you do it right the first time, all the rest come along more or less for free (if you're working in a spreadsheet). Spend some time looking at the SEDs. Look at their similarities and differences. Identify the bad ones, circle back to fix or patch photometry if necessary. Discuss with the others what to do and why. Make sure to keep careful track of those things that are limits rather than detections.
Another try at explaining:
- What do you have? JHK & WISE data in Vega mags. IRAS data in Janskys.
- What do you need to get? everything into Jy, which are units of Fnu. Then convert your Fnu in Jy into Fnu in cgs units, ergs/s/cm2/Hz, so multiply by 10^-23. Then convert your Fnu into Flambda in cgs units, so multiply by c/lambda^2, with c=2.99d10 cm/s and lambda in cm (not microns!). Then get lambda*Flambda by multiplying by lambda in cm. Plot log (lambda*Flambda) vs. log (lambda).
- Once you make your first SED correctly, the rest are easy. But that first one is hard.
- Then you need to look through each of the SEDs and decide which look like you expect, which need photometry to be checked, and which seem unlikely to be stars. This is a judgement call, and your judgement will improve with time as you gain some experience.
Questions for you:
- Which objects look like they have excesses? Which don't?
- What do the IR excesses look like in your plots? Do they look like you expected? Like objects in Monday's ppt or elsewhere?
- Find the object in this list of five with zero IR color. What are the WISE magnitudes? How does this fold into the Vega-based definition of magnitudes and some of the talks on Monday?
- EXTRA CREDIT: add a Rayleigh-Jeans line to your SEDs, anchored at K-band (2.2 um). (Hint: answer to prior question!)
- Why did we do this step? (What is the point?)
Checking that the coordinates and photometry make sense, part 2 - SED inspection
In an ideal world, you'd make all the SEDs for all the bands to which we have access, compare them to the notes you've already made about the images, identify those with photometry issues and fix those (manually if necessary), AND make SEDs again. If you were programming in Python, you'd have a shot at making a first pass at fully-populated SEDs in less than an hour or two, but even for me, tracking down all the photometry issues was ~2-3 days. Let's not waste that time right here, right now; let's use my SEDs and jump into the next step.
Relevant links:

PRACTICE SED: What's the deal with this one (why does it look like this)? (In my SED, the y-axis units are cgs units [sorry], *=new optical data, +=optical literature data, diamonds=2mass, circles=irac, stars=WISE, arrows=limits, and boxes=MIPS if they exist, which they don't here.) (Note that this example comes form last year but is still good for us to look at. Then, they were worrying about Spitzer vs. WISE; now we are worrying about WISE vs. IRAS. ...Same idea!) THINK about your answer BEFORE READING ON!...
Answer: This source is near a bright nebulous patch in the WISE images that either is being inappropriately tagged as a point source (with its flux densities attached to this source) or whose brightness is contaminating the photometry beyond recovery. The Spitzer data are critical for sorting out what is going on here. There is something going on with the optical data - it's apparently wrong for this source, but this is the best possible match given the information we have in the literature, so maybe the people who wrote the paper with the optical data screwed something up either in bandmerging or in their photometry.
More words:
Obtain my set of SEDs from email. In my SEDs, I use the following symbols for particular surveys. Vertical black lines through any point is the error on the point; in many cases, the error bar is very small. Go through all of the SEDs. You will need to look for three or four things -- see the questions below. Keep notes on this.
| symbol | color | survey |
|---|---|---|
| + | cyan | literature optical UBVRI |
| + | black | SDSS ugriz |
| diamond | black | 2MASS JHKs |
| square | blue | Denis IJKs |
| circle | black | Spitzer IRAC |
| stars | black | WISE |
| x | yellow | Akari IRC, FIS |
| triangle | cyan | MSX |
| square | black | Spitzer MIPS |
| upside down triangle | red | IRAS PSC, FSC |
| actual arrow | black | limits at any band |
Questions or Tasks for you:
- Go through the sources assigned to you and your partner. Make notes on the SEDs, including any you would like to discuss with more people (e.g., discuss with the group). As you go through, specifically consider the next few questions as well.
- Make a list of sources where there are things that seem wrong in the SED - things suggestive of a source mismatch (e.g., source seen at optical is NOT source seen at NIR, is NOT source seen at MIR, etc) - or things suggestive of a photometry problem. We can use this information to circle back and repeat the search for photometric matches above. (In fact, I did exactly this over the course of about 2-3 days.)
- Make a list of sources where IRAS fluxes are too bright given the new WISE information. This is another facet of one of our big science goals - seeing where WISE resolves source confusion means both where there are multiple sources and where there is just high surface brightness from the nebulosity contaminating the IRAS measurements.
- Make a list of sources whose SEDs suggest that they may be non-stellar. This is yet another facet of our science goals - identifying which objects are not likely red giants.
- As you are going along, can you tell at a glance whether or not any given object has an IR excess? (This may be easier if you managed to put an RJ (Rayleigh-Jeans) line on your SEDs, but still.) What constitutes an excess? Where are you looking to compare points to see whether or not there is an excess? (These are all leading questions, setting up the next several steps.)
- What bands do we have for the most sources?
- Why did we do this step? (What is the point?)
Calculating excesses, part 1
Probably above, when I asked which points you were comparing to see whether or not there is an excess, you were comparing points near the peak of the photosphere portion of the SED to the longer wavelengths.
Sometimes it's really easy to decide whether or not a given object has an IR excess. By now, you should already have found some SEDs that have obvious excesses. But, how big of an excess does it have?
Now, we need to start moving towards formally, mathematically, calculating whether or not these stars have an excess. To do this, we need to compare measurements at a relatively short wavelength to a relatively long one. This will make the most sense for the most stars if we pick bands that are available for the largest fraction of stars out of our sample.
Pay attention to detections (not limits).
Questions or Tasks for you:
- What relatively short wavelength band do we have for the most stars?
- What relatively long wavelength band do we have for the most stars?
- Depending on what you got for the answers to the prior questions, try calculating K-[22] for the ensemble of stars, or [3.4]-[22], or some other combination you think is a good idea.
- What value of K-[22] or [3.4]-[22] (or your other combination) do you expect for stars without circumstellar dust? Why?
- Why did we do this step? (What is the point?)
Calculating excesses, part 2: Making CMDs
Relevant links:
- Color-Magnitude and Color-Color plots
- Finding cluster members
- Also see slides from my set of talks on Monday.
In looking for stars with excesses, it will help to look at the distributions of K-[22] or [3.4]-[22] (or whatever other combination you've found above) as a function of other parameters.
Make a color-magnitude diagram for the ensemble of sources. K vs K-[22] and/or [3.4] vs. [3.4]-[22] are good places to start, but feel free to try other combinations. Pay attention to detections (not limits). You may want to use IRSA Viewer rather than Excel because then you can pick out individual sources that are outliers and see immediately which source they are. However, you need to get the catalog into IPAC Table format first in order to make that happen, so you may decide that Excel is easier.
You may want to start color-coding points based on the sample from which they come (de la Reza original? Joleen's unbiased sample?).
- Are there any sources that you can tell right now have large excesses?
- Are there any sources that you can tell right now have major photometry problems?
- Are there sources where you are undecided if they have excesses? (hint: yes.)
- BONUS: add some error bars to your diagram.
- Why did we do this step? (What is the point?)
Calculating excesses, part 3: Making different color-color diagrams
In order to formally decide if a star has an IR excess, we need to define what is NOT an IR excess.

- On Monday, what did I say should be the IR color of plain photospheres?
- On Monday, I also showed a movie of blackbody curves as a function of temperature. (it is here if you want to view it again: https://www.youtube.com/watch?v=mjfSy2kHWqQ ) When might the IR color of plain photospheres change?
- One way to decide if we need to worry about this is to plot things as a function of temperature. Out of the data that we have, are there any color indices that are a sensitive function of temperature? (Hint: watch the movie again)
- Try plotting V-K against K-[22] or [3.4]-[22]. Are there any we need to worry about? (you can get a grid of expected colors as a function of spectral type from me.)
- What should the predicted [3.4]-[22] be in this equation?
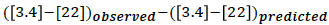 Now you should have a better sense of what this equation might mean.
Now you should have a better sense of what this equation might mean. - Are there still objects for which you are unsure if they have IR excesses? (hint: yes)
- Look at this SED on the right hand side. Does it have an excess? That vertical bar is the error bar. It's big, at least comparatively. If you extend an RJ line from K band (2.2 um), what if that RJ line hits the lower portion of the plot symbol at 22 um? Is that an excess? Is that a significant excess? How would you know? (Hint: this is setting up the next steps!)
- Why did we do this step? (What is the point?)
Calculating excesses, part 4: Significance of excesses
By now, you should already have found some IR excess objects. But, especially for this data set, we have a LOT more sources where the IR excess is ambiguous. You can't necessarily tell just by looking at the SED or the color. You need to calculate whether or not it has an excess, and you need to worry about the uncertainty on the measurements (the measurement errors).
 Here is the calculation from our proposal. You now know what to put in the numerator. The denominator is the uncertainty on the color. To get the uncertainty on the color, add the uncertainties from each point (that goes into the color) in quadrature. What this means: (error on x-y)^2 = (error on x)^2 + (error on y)^2. Note that even though we are calculating the difference in values (x-y), the errors still ADD (in quadrature).
Here is the calculation from our proposal. You now know what to put in the numerator. The denominator is the uncertainty on the color. To get the uncertainty on the color, add the uncertainties from each point (that goes into the color) in quadrature. What this means: (error on x-y)^2 = (error on x)^2 + (error on y)^2. Note that even though we are calculating the difference in values (x-y), the errors still ADD (in quadrature).
This chi is an estimate of significance -- the signal divided by the noise, or the measurement divided by the error. Chi values that are greater than 3 have a 99.7% chance of being a real excess. Calculate chi values for various combinations that you have decided are important.
Questions:
- Make another color-mag or color-color diagram as you did above, but this time identify sources with excesses (with your chi greater than 3) by making them a different point shape or point color. Where do the stars with excesses fall in the diagram? You may also wish to make different plots for different subsamples or different symbols for the different subsamples.
- Pick some of the objects that have small excesses and go check out their SEDs. Are their excesses based solely on one point or is there corroborating evidence for an excess from another wavelength?
- Can you find objects where chi calculated for two bands does NOT agree with the chi calculated for another two bands? Go get the SEDs for them and see if you can figure out why the math is coming out the way that it is.
- Why did we do this step? (What is the point?)
Calculating excesses, part 5: Further muddying the waters
Astronomical data are VERY hard to precisely calibrate. The 2MASS folks, the Denis folks, and the WISE folks (and for that matter, all the other teams too) all calibrated their instruments slightly differently. It could be that small excesses we measure are not real dust around the star, but absolute calibration uncertainties in the way the data were reduced. Are there any sources for which you are worried that this might be the case? In this sense, since the WISE bands were all calibrated the same way by the same people, a comparison of two WISE bands may be the most sensitive measure we can have of IR excess.
These stars intrinsically vary. K measured at one time may not be at all the same as the K measured at another time, and not for source mismatch reasons, but real, astrophysical variations -- our Sun has sunspot cycles, and other stars do too. If one measurement was obtained at a low point in the starspot cycle, and another measurement was obtained at a high point in the starspot cycle, the measurements will be legitimately different. In that sense, since the WISE bands were obtained essentially simultaneously, WISE data should be the best data for a comparison of two bands, since the star itself will not have had time to significantly change between WISE measurements.
One way to constrain this is to look at the individual WISE exposures that go into the mean WISE phot we have used. One recent paper finds in some cases that the mean of the photometry of the object on the individual frames is significantly different than the photometry reported from the Atlas mosaic. If we are going to write this up in a journal article, we may need to worry about this.
Many of our stars are saturated in WISE 1 or 2. Patel et al. 2014 present an approach for 'correcting' the saturated WISE values to obtain viable estimates of the true brightness of the star at these bands. It is most badly needed for WISE 2, on which we've not been focusing. The WISE 1 corrections are relatively small between 4.5 and 8.4 mags. Does that help us include more sources in our work?
Why is this step here? (What is the point?)
Comparison to the literature and start of the bigger picture
Here you will start to see how the language of science evolves with time. When IRAS was flying, most of the people who worked with IR data were coming at it from the radio, so they thought in Janskys. This is why the IRAS catalog is in Janskys. With the revolution mostly driven by Spitzer (but also ISO, Herschel, WISE), many more astronomers from other wavelengths were drawn into IR astronomy, and many of those astronomers did not think in Janskys, but in magnitudes. So, color-magnitude and color-color diagrams now are shown explicitly in magnitudes. But this was not necessarily the case when Siess and Livio (1999) wrote their paper, or when de la Reza et al (1996, 1997) was published.

Look at Siess and Livio (1999), figure 10 (click on tiny image here on the right to load it). It says it is reproduced from de la Reza et al (1996). Similar plots appear in de la Reza et al. (1997), figs 1 and 2.
- What does it say it is plotting?
- Derive (do the math!) to show how to convert what it says its plotting (in fluxes) into actual colors/magnitudes. Remember that m1-m2 = 2.5 log(f2/f1)
- What is weird about this plot? I can think of at least 2 things.
- This plot is critical to their interpretation of the IRAS data in their model. Can you reproduce this plot using magnitudes and the IRAS FSC measurements for everything?
- Which of the points on this plot are compromised as per your investigations above? (multiple sources, wise doing a better job of determining flux from the source, not a giant)
- Do you think that their model still holds using the IRAS data, informed by the other data we have assembled above?
- Why did we do this step? (What is the point?)
The bigger picture
Now, it's time to pause, take a breath, and see if we can address some of the larger questions raised in our proposal.
- For each sub-sample, what is the IR excess fraction? At what wavelengths?
- For the Carlberg sample (the cleanest with respect to input biases), plot a measure of IR excess (your choice) vs. some of the parameters that Carlberg thought were important in her paper -- vsini, A(Li), Vmag, carbon isotope ratio, and anything else you can find. Do you see anything that is worth thinking more about?
- Why did we do this step? (What is the point?) Could we have done this step earlier?
TO-DO ITEMS
- DONE Luisa to clean up limits in code such that lower/upper limits make sense in catalog and plots
- DONE Luisa to fix photometry issues for those identified from the SED inspection as being bad. (Also, see if we can reconstruct some of he WISE 1-2 values, based on the saturation correction from Patel+ or just by looking more closely at data quality flags.)
- DONE Luisa to investigate whether it makes sense to swap DENIS K in for 2MASS K where there is no 2MASS K.
- DONE Luisa to remake the SEDs for those with fixed photometry.
- (Luisa has made headway on) Make clear and complete lists of those objects that break into pieces in IRAS, those that have coordinate issues, and those that have SEDs inconsistent with stars. Keep track of which sources came from which original catalog such that we can report, e.g., "xx% of the sources published in de la Reza break into pieces when viewed with WISE."
- Integrate notes from image inspection with the SED inspection (e.g., in more detail). Combine cells and information where needed to make as concise as possible.
- For each "not a star", search in Simbad and the literature to see if anyone has any other information about the object.
- Extra credit options: add errors to SEDs. Add Rayleigh-Jeans line to SEDs.
- WATCH FOR LIMITS. make plots of just detections, not limits.
- Make some color-color and color-mag diagrams for subsets of data by original catalog, AND/OR color-code the points in the diagrams to match original source catalog.
- Investigate the photometry on those with VERY large K-[22] or [3.4]-[22]. Are values greater than 6 real, physical values? What do those SEDs look like?
- Find objects where the chi is insanely large. Are those real? What do those SEDs look like? Are the chi values we calculate realistic?
- Find objects where chi calculated for two bands does NOT agree with the chi calculated for another two bands? Go get the SEDs for them and see if you can figure out why the math is coming out the way that it is.
- Do some analysis on the ensemble of points for K-[22] and [3.4]-[22] to see which distribution makes more sense, incorporates more objects, has lower scatter. Decide which we should use in the end.
- Investigate whether [4.5]-[22] would be worth considering. Note that the correction for saturated WISE2 is much larger than the correction for WISE1.
- Worry about those with chi near to but not over 3. Are there any reasons we should take them as IR x sources?
- What about plots vs. chi?
- Can we reproduce plot from literature? Where are the obj that we know are not stars, or for which wise indicates lower fluxes than iras?